【Natural Language Processing】1 Word2vec (1)
Source: CS224n, Natural Language Processing with Deep Learning
1 Introduction to NLP
- complexity of communication enabled by language is a uniquely human intelligence among species
- Human children, interacting with a rich multi-modality world and various forms of feedback, acquire language with exceptional sample efficiency (not observing that much language) and compute efficiency (brains are efficient computing machines!)
A few applications of NLP
- Machine Translation
- failures of these systems for most of the world’s 7000 languages, difficulties in translating long text, and ensuring contextual correctness of translations make this still a fruitful field of research.
- Question answering and information retrieval
- Summarization and analysis of text
- NLP tools can be powerful for both the increase of access to information to the public, as well as surveillance, corporate or governmental.
- Speech-to-text
In all aspects of NLP, most existing tools work for precious few (usually one, maybe up to 100) of the world’s roughly 7000 languages, and fail disproportionately much on lesser-spoken and/or marginalized dialects, accents, and more. Beyond this, recent successes in building better systems have far outstripped our ability to characterize and audit these systems. Biases encoded in text, from race to gender to religion and more, are reflected and often amplified by NLP systems. With these challenges and considerations in mind, but with the desire to do good science and build trustworthy systems that improve peoples’ lives
2 Representing Words
2.1 Independent vectors for different words
- Simplest way to represent words is to use unrelated vectors (as a set)
Type is an element of a finite volcabulary
Token is an instance of a type observed in some context
We can store different words as independent standard basis (1-hot vector) of , i.e.
We encode no similarity or relationship in this vectors, for different word vectors have inner product :
and plus they are apparently not ordered.
2.2 Vectors from annotated discrete properties
We can construct word vector by the relationships that a word posess in the categories of grammar and other words.
Failures of this method
- Human annotated resources are always lacking in vocabulary compares to methods that can draw a vocabulary from a naturally occuring text source
- A tradeoff between dimensionality and utility of the embedding—it takes a very high dimensional vector to represent all of these categories, which is costly and always incomplete.
- Human ideas of what the right representations shoud be for text tend to underperform methods that allow data to determine more aspects
3 Distributional semantics and Word2vec
- We can learn rich representations of items using deep learning by means of unsupervised learning or (self-supervised learning)
- Unsupervised learning or self-supervised learning attempts to learning by predicting the remianing parts of data using unmasked parts.
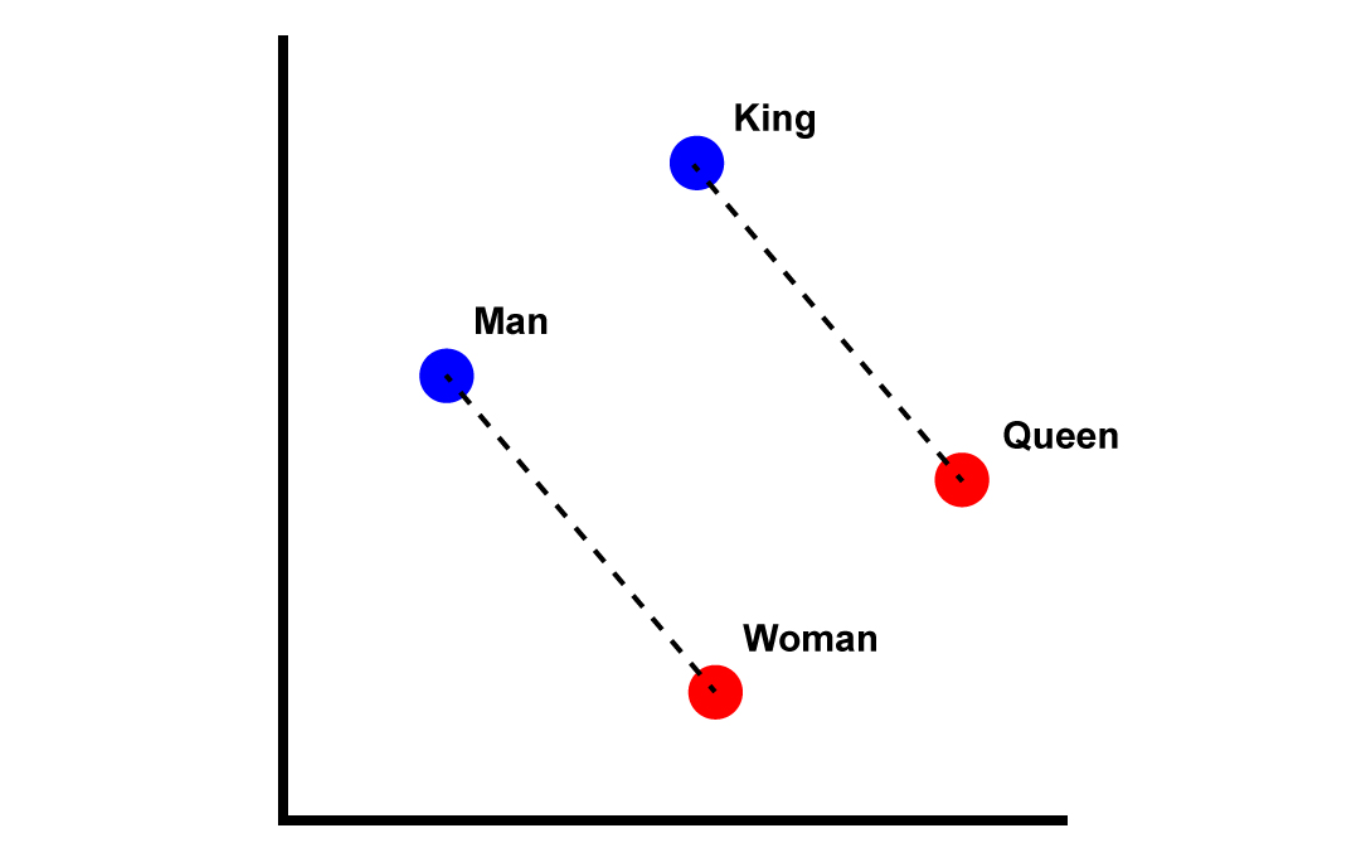
- You should know a word by the company it keeps.
- Words can be imagined as distributions over the semantic space where similar words appear nearer.
3.1 Co-occurrance matrices and document contexts
One idea of co-occurrance may be the following
- Determine a vocabulary
- Construct zero matrix of shape
- Count the co-occurrances and fill in the matrix
- Normalize rows by their sums
Assume the matrix is notated as , then word vectors of each word in vocabulary is the rows of the matrix:
We can use various criterions to determine whether two words co-occurr, as the following shows:
in which the subscripts of the brackets tells the radius of the co-ocurrance range and the black triangle indicates the central word tea.
Failures of this method
- Higher-dimensional vectors tend to be unwieldy
- Raw counts of co-occurrences over-emphasize the importance of common words such as the. Taking log frequency tend to be useful.
- Refer to GloVe (Pennington et al. 2014)
3.2 Word2vec
Skipgram word2vec model learns a short vector of words by peeking into a small contexts of words.
We have finite vocabulary , let be random variables representing unknown pair of words with representing center word and representing an outside word and let and represent specific values of corresponding values of these random variables.
Let be matrices and each word in is associated in the corresponding row in and .
Skipgram word2vec
The word2vec model is as follows
in which refers to row of corresponding to word . Note that
is the probabilites of all words given the center word , which is similar to the row in the co-occurrance matrix .
Then we learn to optimize the cross-entropy loss with the true distribution :
Questions
- How do we perform the min operation?
- How do we get the random variables?
- Why the negative-log of the probability?
- Why is this much better than the co-occurrance counting?
- Why not all distributions over and can be represented by this model?
3.3 Estimating a word2vec model from a corpus
Word2vec empirical loss
Consider how we estimate the expectation term in the aforementioned model, we perform empirical loss. Let be a set of documents , where each contains a sequence of word with all and let be a positive-integer window size. For all center word , we take the words within the window size, i.e. to estimate the expectation term:
Gradient-based estimation
We first initialize the matrices and by drawing entries from gaussian distribution such as and preform gradient descent on :
Stochastic gradient
Summing over the entire set of documents can be expansive, so we update matrix every time when having seen only as few of them:
for some integer .
3.4 Calculating gradient
By the linearity of gradient operator, we have
We can split the term in blue into two terms by the properties of log function and the linearity of gradient operator:
When observing the second term, one can derive that
Thus the whole gradient term can be simplified as
which is in align with the intuition: upgrade the word vector towards the opposite direction of the expectation.
3.5 Skip-gram with negative sampling (SGNS)
Notice that calculating the following softmax function can be expansive due to the denominator:
which normalizes the vector. The skip-gram model encourages and to be similar and and to be different:
where is drawn from some distribution .