【DatawhaleML】 4 支持向量机
支持向量机 (Support Vector Machine)
1 间隔和支持向量
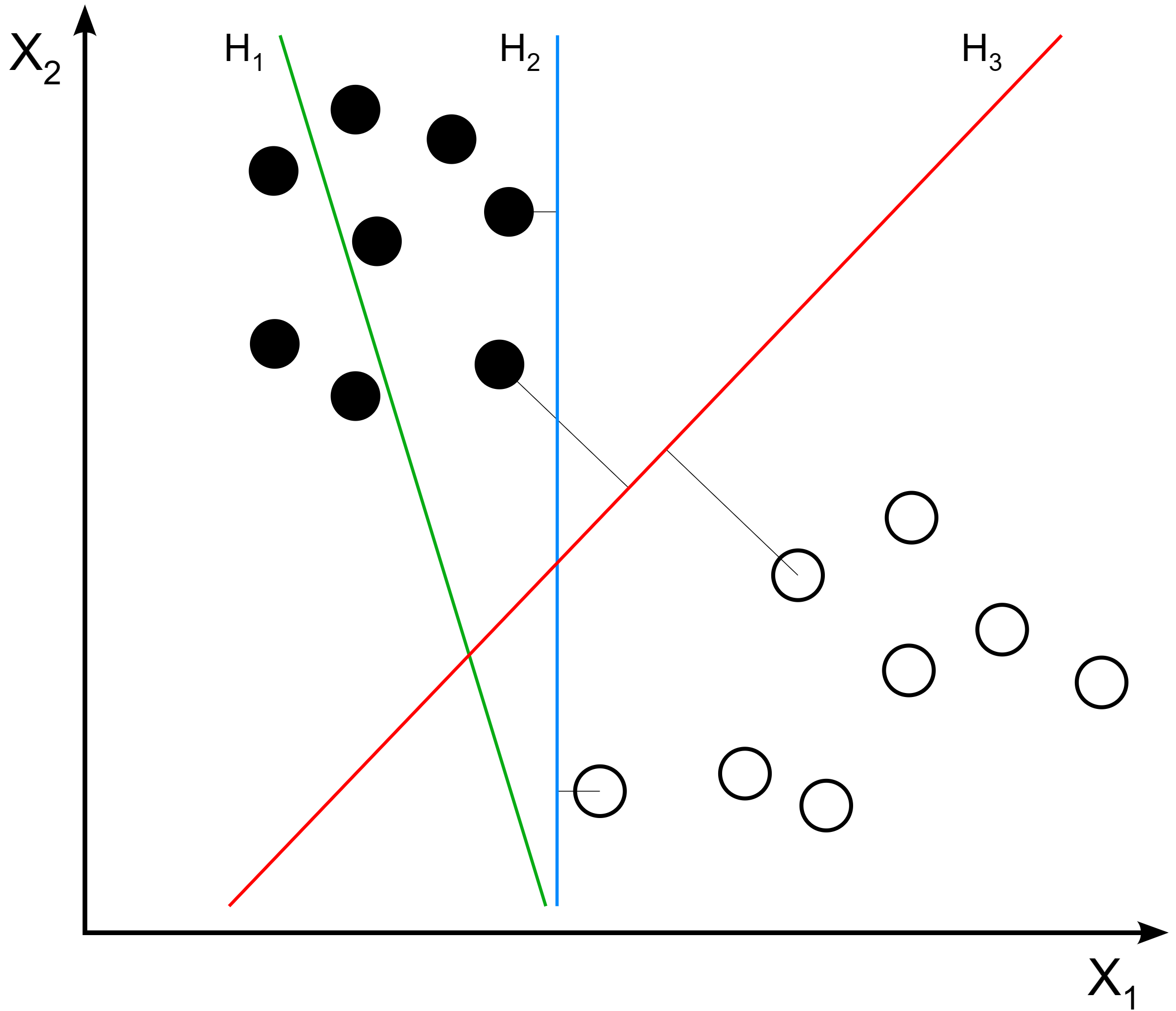
考虑二分类问题,其训练集为,,分类的主要目标为找到一个超平面,使得这个超平面可以将这两类样本尽可能分开,如下图所示。但对于有限的样本,可以将训练集正确分开的这样的超平面不止一个,我们需要选择一个“最好”的超平面作为我们的判别依据。
事实上,我们可以这样考虑。由于训练样本只是真实样本空间中的一个采样,在不断接受新样本的时候,我们希望在训练样本上训练得到的划分准则依然可以起到较好的作用,也即具有较好的鲁棒性 (Robustness)。具有这样特征的模型,我们也称它具有一定的泛化 (Generalisation) 能力。
超平面可由方程确定,其中为权重向量,为偏置。样本空间中的点到超平面的距离为。
点到超平面距离的计算
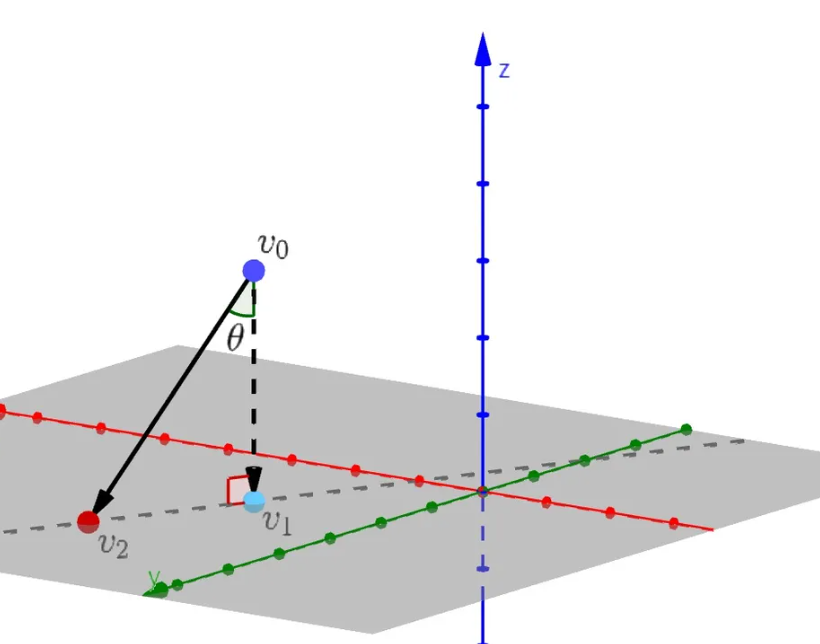
给定超平面外一点,令为在超平面上的投影点,为超平面上任意一点,问题在中的情形如下图所示。
于是。 根据向量夹角公式,有。由于是超平面的法向量,于是有。又因为和垂直,于是存在某个,有。所以
假设超平面可以对样本进行正确分类(假设没有样本点恰好落在超平面上),令
于是存在一些距离超平面最近的样本点使得上式中的某一个等号成立,这些样本点被称为支持向量 (Support Vector)。反过来讲,这些支持向量可以将分类超平面完全确定,如下图所示。考虑两个属于不同类别的支持向量,可以验证它们到超平面的距离之和为,这被称为间隔 (Margin)。
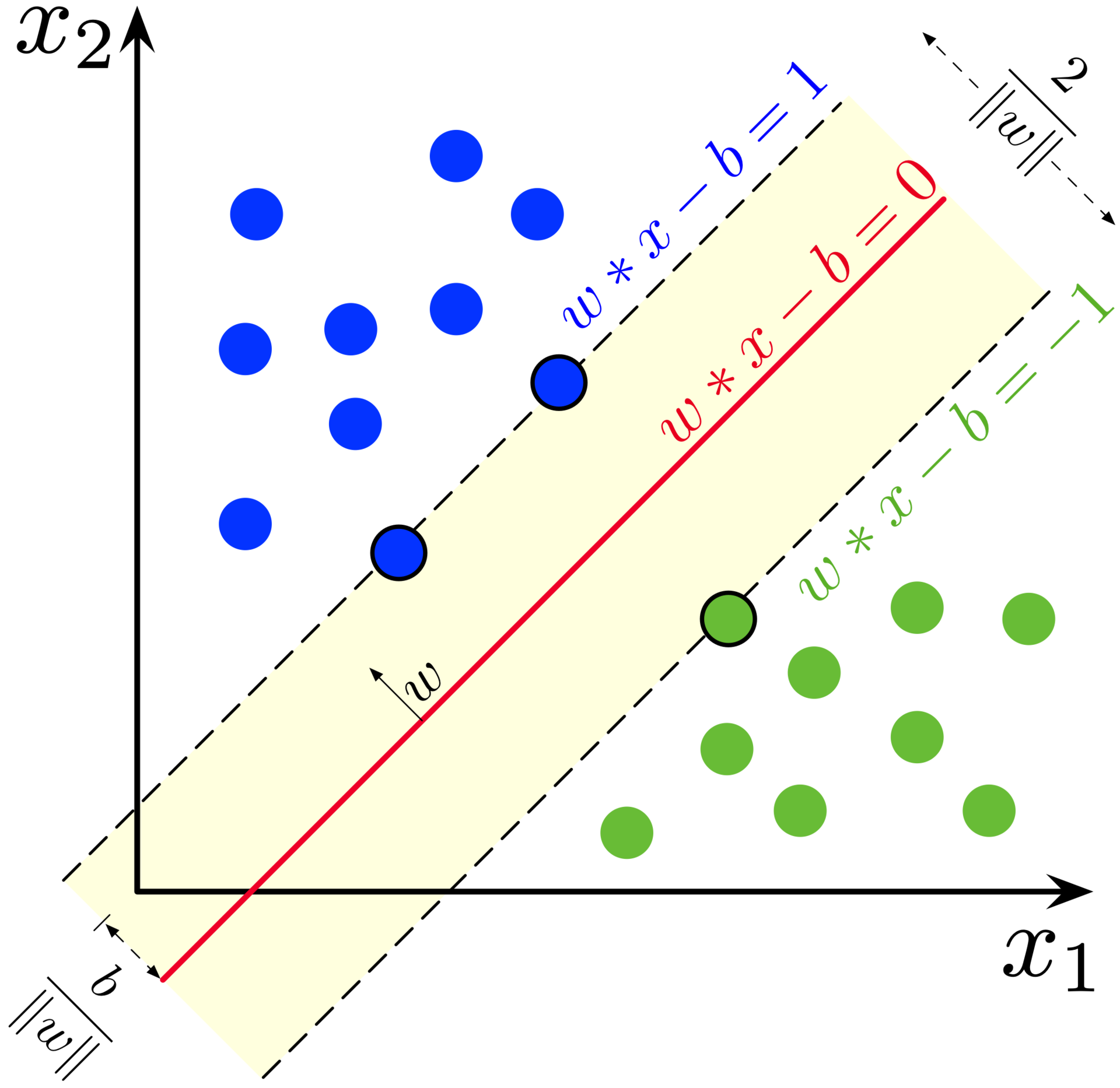
回顾上文中提到的我们的目标,是要找到泛化能力最好的那一个超平面,一种自然的思路就是让划分间隔越大越好,也即将两类分的越开越好。于是可以得到下面的优化问题
显然这等价于最小化权重向量长度的平方,于是上述优化问题可以改写为
这就是支持向量机 (Support Vector Machine)模型
2 对偶问题 (Dual Problem)
2.1 Lagrange 对偶问题
TODO:对偶函数和对偶问题的直观意义
对于优化问题,我们将每条约束与Lagrange乘子,得到该问题的Lagrange函数
其中为所有Lagrange乘子堆叠形成的向量。注意到是一个关于和的凸函数 (Convex Function),将其分别对和求偏导,并令偏导为零,可得
进而可以得到Lagrange对偶函数 (Lagrange Dual Function)
这样一来,原问题可以转化为最大Lagrange函数下界的对偶问题:
通过求解最优的后,将结果代入式中即可得到模型。
2.2 Karush-Kuhn-Tucker 条件
下面不加证明的引入两个定理:
定理 对偶函数一定是凹函数 (Concave Function)
定理 假设原问题最优解的目标函数值为,则
由于对偶函数是凹函数,于是对偶问题为凸优化问题,假设其最优解为,对应的最优函数值为
- 若,称为弱对偶 (Weak Duality),并定义为对偶间隙 (Duality Gap)
- 若,称为强对偶 (Strong Duality)
若原优化问题和其对偶问题是强对偶关系,假设和分别为原问题和其对偶问题的最优解,则下面的条件称为 Karush-Kuhn-Tucker条件,简称KKT条件 (KKT Conditions) :
上面的互补松弛条件看起来不是很显然,这个条件表明,当时,;当时,。现在给出证明:
注意到过程中的两个小于等于号只能取等号。于是。又因为求和式中的每一项不大于零,于是只有。观察上述的KKT条件,不难发现只有数据中的支持向量才对模型做出了贡献。而其他大规模的样本并未真正参与。
2.2 对偶问题的求解
本节以SMO (Sequential Minimal Optimization) 为例讨论上述优化问题的求解方法。由于参数向量拥有多个分量,不妨考虑固定除两个分量和以外的其他所有分量后,优化受限制的目标函数直至收敛,则就是SMO的主要思路。
考虑随机选取的两个分量和,第二个稳定性条件可以简化为以下两项
消去变量后,原目标函数变成了单变量二次函数可以直接计算解析解。
在得到权重向量之后,可以通过支持向量计算偏置。对于任何支持向量,有
于是考虑更加鲁棒的计算偏置方法
3 核函数 (Kernel Function)
3.1 核技巧 (Kernel Trick) 和核函数 (Kernel Function)
考虑使用线性模型分类异或问题的情形,不难发现一个线性分类器无法实现(当然,可以通过多个线性分类器实现)在本节我们考虑另一种方法。若可以找到一个映射$\phi$,将低维空间中的数据点嵌入高维空间,使得高维数据可以线性可分,就可以直接应用线性分类器的方法了。
将映射$\phi$应用于样本向量,在特征空间中的超平面就变为
类似地,优化问题就变为
对偶问题就变为
考虑到高维或无穷维空间下计算向量内积较为困难,我们采用核技巧 (Kernel Trick)规避这一问题。定义函数
这样对偶问题的目标函数可以简化为
这里的$\kappa(\cdot, \cdot)$称为核函数 (Kernel Function),求解后的线性分类器即为
这被称为支持向量展式 (Support Vector Expansion)
3.2 再生核 Hilbert 空间 (Reproducing Kernel Hilbert Space)
4 软间隔 (Soft Margin) 和正则化 (Regularisation)
5 支持向量回归
6 核方法 (Kernel Methods)
6.1 RKHS 上的表示定理
6.2 核线性判别分析 (Kernel Linear Discriminant Analysis)
7 支持向量机的求解
7.1 Nystrom 近似 (Nystrom Approximation)
7.2 随机 Fourier 特征 (Random Fourier Features)
参考文献
[1] Alexey Zaytsev, Scalable Kernel Methods: Overview
[2] https://zhuanlan.zhihu.com/p/64580199
[3]