【UCBerkley DRL】 7 Value Functions
Lecture 7 Value Functions
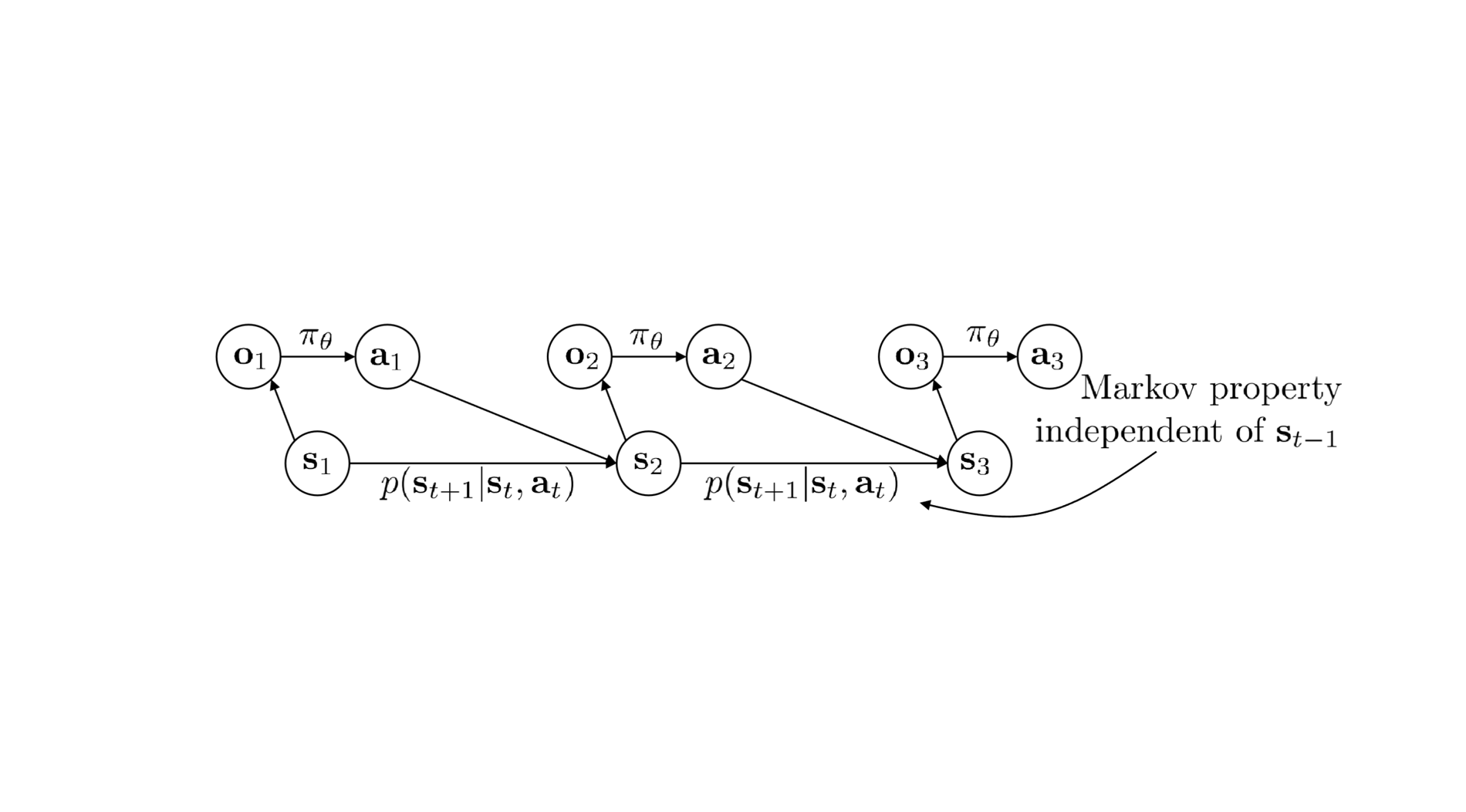
1 Recap: Actor Critic
1.1 Actor Critic
1.2 Omit Policy Gradient
2 Policy Iteration
2.1 Policy Iteration
2.2 Dynamic Programming
2.3 Policy Iteration with Dynamic Programming
2.4 Simpler Dynamic Programming
3 Fitted Value Iteration & Q-Iteration
3.1 Fitted Value Iteration
3.2 Fitting without Transition Dynamics
3.3 The “max” Trick
3.4 Fitted Q-Iteration
4 Q-Learning
4.1 Off-policy
4.2 Optimization Variables and Target
4.3 Online Q-Learning Algorithms
4.4 Exploration
5 Value Functions in Theory
5.1 Value Function Learning Theory
5.2 Non-tabular Value Function Learning
5.3 Fitted Q-Iteration
All articles in this blog are licensed under CC BY-NC-SA 4.0 unless stating additionally.